4 Bases de datos
4.1 Introducción
Una base de dato una colección de datos relacionados entre sí [1]
Los datos en una base de datos pueden ser de cualquier temática y se pueden buscar, ordenar y agrupar en conjuntos.
A día de hoy en el que las aplicaciones informáticas están en plena expansión, las bases de datos evolucionan de forma paralela ya que para la mayor parte de estas aplicaciones se hace necesario el almacenamiento y posterior tratamiento de los datos, ya sea recogidos por la interacción del usuario o generados de forma previa al uso de la aplicación.
Los datos que se almacenan en una base de datos dependen de su naturaleza: se pueden almacenar datos alfanuméricos, numéricos, archivos completos e incluso imágenes. En función de cómo deben estar relacionados estos datos y su tratamiento se puede elegir un modelo de base de datos u otro. Existen varios modelos de datos tal y como se verá más adelante.
En cuanto al ámbito de aplicación al que este documento se refiere, las bases de datos son en formato digital y su gestión se realiza con programas informáticos denominados Sistemas Gestores de Bases de Datos (SGBD).
"Un sistema gestor de bases de datos es un aplicación software que permite al usuario o a otras aplicaciones interactuar con bases de datos, permitiendo definir, crear, consultar y administrar los datos almacenados en tablas." [1]
Los SGBD proporcionan las funciones que permiten la administración de la base de datos y los datos almacenados en ella. Las funciones proporcionadas se clasifican en cuatro grupos principalmente:
Definición de datos. Creación, modificación y borrado de la estructura de los datos. La estructura de los datos en un modelo relacional son las tablas y en un modelo no relacional como MongoDB son documentos.
Actualización de datos. Inserciones, modificaciones y borrado de los datos contenidos en las estructuras. Estos datos están organizados en filas y columnas para un modelo relacional y en clave-valor en un modelo no relacional como MongoDB.
Extracción de datos. Consultas sobre los datos almacenados, pudiendo realizarse de una forma simple: extrayendo datos de una sola estructura o de una forma más compleja: combinando los datos de varias estructuras para formar un conjunto de datos relacionados.
Administración de las bases de datos. Registro y gestión de usuarios, seguridad en el acceso, mantenimiento, integridad en los datos, concurrencia etc.
Por otro lado, toda base de datos debe cumplir una serie de normas o estándares en cuanto a la forma de gestionar el acceso a los datos. En función del modelo de datos utilizado se debe cumplir un estándar u otro.
"Para garantizar la consistencia de los datos y las funciones realizadas sobre los mismos las bases de datos relacionales siguen las características definidas en el estándar ACID: Atomicity, Consistency, Isolation and Durability." [2]
Atomicity (atomicidad). Asegura la ejecución de transacciones completas, de forma que si una transacción está compuesta de varias operaciones, o se ejecutan todos o no se ejecuta ninguno.
Consistency (consistencia). Asegura que las operaciones realizadas sobre los datos siguen la norma de integridad de la base de datos. Si hay algún fallo o inconsistencia, el dato vuelve al estado anterior a la transacción ejecutada.
Isolation (aislamiento). Asegura la concurrencia de operaciones sobre los datos, de forma que una operación no puede afectar a otras.
Durability (durabilidad). Asegura que las operaciones realizadas sobre los datos persistirán y aunque falle el sistema, los datos seguirán disponibles en un estado correcto
El problema de ACID es que no se pueden cumplir todas las cualidades en sistemas muy grandes ya que no escala:
En transacciones con volúmenes bajos, las latencias que permiten a las bases de datos ser consistentes no tienen un efecto notable en la experiencia de usuario, [...] pero a medida que la actividad aumenta estos puntos en el rendimiento comenzarán a limitar el crecimiento y a crear errores. [3]
Esto es debido a la propiedad "I", es decir, aislamiento. Si por cada transacción de un usuario sobre la base de datos miles de usuarios conectados de forma concurrente tienen que esperar a que acabe para evitar interferencias, el sistema se vuelve lento e insostenible. Debido a esto surge el teorema CAP.
El teorema CAP surge en el año 2000 por Eric Brewer en un simposio sobre los principios de computación distribuida (PODC). El acrónimo CAP significa:
Consistency (consistencia). Un servicio funciona totalmente o no funciona en absoluto. Es equivalente a la atomicidad en ACID ya que indica que una transacción se realiza completamente o no se realiza la persistencia.
Availability (disponibilidad). El sistema funciona completamente o no funciona, es decir, o es capaz de dar respuesta a cualquier petición o no dará respuesta a nadie.
Partition Tolerance (tolerancia a partición). La base de datos actúa como un conjunto atómico cuando hay particiones, de forma que funciona o no sin provocar inconsistencia de datos.
Lo que Brewer defendía es que solo se pueden elegir dos de estas tres características en un sistema distribuido:
Puedes tener como mucho dos de las tres propiedades CAP en cualquier sistema de datos distribuido [4]
Habrá tres alternativas dependiendo de las características elegidas y en función de la alternativa se tendrán unas ventajas u otras:
| Elección | Características | Ejemplos |
|---|---|---|
| Consistencia y Disponibilidad (Pérdida de particiones) | Commit de 2 fases y protocolos de validación de caché | Bases de datos de un único sitio, Bases de datos en cluster, LSAP, sistemas de ficheros |
| Consistencia y Tolerancia a partición (Pérdida de disponibilidad) | Bloqueo pesimista y hacer que las particiones minoritarias no estén disponibles | Bases de datos distribuidas, Bloqueo distribuido y en la mayoría de protocolos |
| Disponibilidad y Tolerancia a partición (Pérdida de consistencia) | Vencimientos, Resolución de conflictos y optimista | Coda, DNS y Web Caché |
Elección de características CAP -[4]
Estas características son difíciles de conseguir en el estándar ACID por lo tanto surge un enfoque nuevo: BASE.
En el enfoque BASE se pierde la consistencia y el aislamiento en favor de la disponibilidad, el rendimiento y una amable degradación. [4]
El acrónimo BASE significa:
- Basically Available (Básicamente disponible).
- Soft-state (Estado suave).
- Eventual consistency (Eventualmente consistente).
Esto quiere decir que el enfoque BASE es totalmente opuesto a ACID: la base de datos no tiene por qué estar actualizada en cada transacción, puede actualizarse eventualmente para ser consistente, en cambio da mucho más peso a la disponibilidad y a la tolerancia a fallos.
Estas características han sido ampliamente adoptadas en la comunidad NoSQL y han influido en el diseño de bases de datos no relacionales, que dan más importancia a la disponibilidad que a la consistencia.
4.2 Modelos
"Un modelo de base de datos proporciona una especificación describiendo cómo se estructura y utiliza una base de datos" [5]
Es decir, cómo se almacena y recupera la información. En cuanto al ámbito de este proyecto se refiere, va a estar centrado en bases de datos relacionales y en bases de datos NoSQL.
4.2.1 Bases de datos relacionales
Este modelo de datos es uno de los más utilizados en las bases de datos. Fue desarrollado en 1970 por E. F. Cood y se usa desde principios de los 80.
Una base de datos relacional basa la estructura de sus datos en tablas y cada tabla organizada por filas y columnas. Cada tabla debe tener un nombre único dentro de la base de datos y cada fila de una tabla debe ser única, es decir, no puede haber duplicidades. Por esto cada fila de una tabla tiene un valor de clave principal o primary key que es único. Cada valor de una fila y una columna se llama campo y los tipos de datos que puede contener son habitualmente valores simples de tipo numérico, caracteres o cadenas de caracteres.
La forma de organizar las tablas es mediante relaciones. Una tabla puede hacer referencia a otra cuando una de sus filas tiene un puntero a otra fila de otra tabla. Esto se hace mediante las claves foráneas o foreign keys, en el que el valor de la clave principal de una fila se almacena en una fila de otra tabla.
Utiliza un lenguaje de consultas llamado SQL (Structured Query Language o Lenguaje Estructurado de Consultas). Este lenguaje es un estándar recogido en la ISO/IEC 9075 y define cómo deben estructurarse los datos y las operaciones sobre dichos datos. Las operaciones básicas que se pueden realizar sobre los datos en SQL son las llamadas operaciones CRUD: Create, Read, Update y Delete o en sintáxis SQL Insert, Select, Update y Delete.
4.2.2 Bases de datos orientadas a documentos
Estas bases de datos son un tipo de base de datos NoSQL. El término NoSQL fue utilizado por primera vez en 1998 por Carlo Strozzi para referirse a su base de datos que seguía un modelo relacional pero no utilizaba SQL como lenguaje de consultas.
Más tarde, en el año 2000 fue cuando se recuperó el término para referir a las bases de datos no relacionales.
Actualmente el término NoSQL es interpretado cómo No solo SQL y representa a los sistemas gestores de almacenamiento no relacionales [6]
En una base de datos orientada a documentos los datos son almacenados en documentos estructurados en un formato estructurado como JSON, BSON o XML. Estos formatos son documentos de tipo clave-valor y tienen una estructura flexible. Gracias a esta estructura puede contener tipos de datos numéricos, caracteres, listas de datos e incluso un documento de tipo clave-valor anidado.
Estas bases de datos no utilizan un lenguaje de consultas estándar como SQL, pero admiten las operaciones CRUD igual que en las bases de datos relacionales.
4.2.3 Bases de datos objeto-relacional
Es un modelo de base de datos que proporciona los beneficios de las bases de datos relacionales y además permite la integración de tipos de datos personalizados, de esta forma un campo en una base de datos podrá contener nuevos tipos de datos.
Los tipos de datos personalizados son objetos que funcionan de igual forma en la programación orientada a objetos, de forma que los campos de una tabla tendrán las ventajas de éstos: encapsulación, herencia y polimosfismo.
Además se pueden definir operaciones y atributos sobre los campos de una tabla como se haría en programación orientada a objetos
4.3 Modelo Entidad Relación. Notación de Chen
Mediante un modelo entidad relación se permite modelar y diseñar la información de un problema del mundo real en entidades, relaciones y propiedades.
Este modelo proporciona un modo cercano y natural de entender las tablas, sus propiedades y la forma en que se relacionan gracias a la semántica utilizada. Es un modelo que está ampliamente extendido a la hora de diseñar esquemas en bases de datos, sobre todo para esquemas en bases de datos relacionales.
Para entender cómo funciona y su utilidad primero hay que definir los términos que se utilizan y cómo se relacionan con el mundo real. [7]
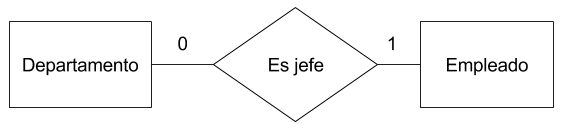
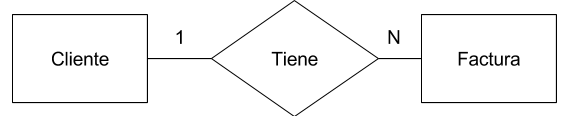
Entidad. Una entidad es un elemento que funciona de forma independiente en el problema planteado. Las entidades pueden ser fuertes cuando tienen existencia por sí mismas, o débiles si solo existen por su relación con otra entidad. Podría ser una persona, una empresa, un proyecto o cualquier cosa que exista con independencia. Una entidad será una tabla en una base de datos relacional.
Atributo o propiedad. Son las características que identifican a las entidades. Cada entidad tiene uno o más atributos que lo identifican y cada atributo es de un tipo, por ejemplo numérico o de texto. La entidad persona podría tener como atributos nombre, apellidos, edad y dirección. Un atributo es una columna de la tabla en una base de datos relacional.
Relación. A pesar de que una entidad tiene independencia se puede relacionar con otras entidades. Por ejemplo, una persona trabaja en una empresa. Esto es una relación entre las entidades persona y empresa.
En función del número de entidades que participen en la relación hay hasta cuatro tipos grados:
Reflexiva o unaria. De grado 1 en el que participa una tabla consigo misma.
Binaria. De grado 2 en el que participan dos tablas.
Ternaria. De grado 3 en el que participan tres tablas.
N-arias. De grado N en el que participan N tablas.
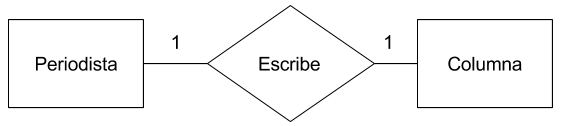
Razón de cardinalidad. Indica el número máximo de instancias de la relación en las que una entidad puede participar con otra. Las razones de cardinalidad de una relación binaria son:
Uno a Uno (1:1). Una entidad A se relaciona con la entidad B una sola vez y viceversa.
Uno a muchos (1:N). Un registro de la entidad A se relaciona con uno o más registros de la entidad B, pero un registro de la entidad B se relaciona con un solo registro de la entidad A.
Muchos a muchos (N:M). Varios registros de la entidad A se pueden relacionar con uno o más registros de la entidad B y viceversa.
Restricción de participación o cardinalidad mínima. Especifica el número mínimo de instancias de relación en las que puede participar una entidad con otra. Puede ser total si cada instancia de una entidad debe estar relacionada con otra entidad o puede ser parcial en el caso de que cada instancia de un entidad puede estar o no relacionada con otra entidad.
A la hora de representar todo esto en un diagrama hay varios modelos para escoger. El modelo que he escogido es el de Chen que utiliza la siguiente notación para cada elemento:


Razones de cardinalidad

Restricciones de participación o cardinalidad mínima